
Динамический ремаркетинг — это возможность напомнить потенциальным клиентам о вашей продукции или услугах, которые раньше были им интересны. На практике этот метод является крайне эффективным и позволяет существенно повысить уровень продаж.
В этом материале мы расскажем, как можно запустить динамический ремаркетинг без обращения к программистам. Вам понадобятся лишь таблицы Google и немножко формул.
Поскольку парсинг таблиц имеет ограничения, из одного файла можно создать фид с ограничением в 1000 товаров.
В зависимости от ваших навыков работы с Google Spreadsheets время на выполнение всех действий может занять от 1-3 часов. Парсинг данных будет производиться из разных файлов, поскольку обрабатывая все в одном файле может начаться путаница, ошибки и проблемы с формулами. После парсинга отдельных файлов необходимая информация будет позже объединяться.
Создание продуктового фида
Под фидом следует понимать простую таблицу с корректными данными, которая будет соответствовать установленным Facebook правилам.
Допустимые форматы файлов: CSV, XML, TSV.
Таблица должна иметь следующие поля:
- id — уникальный код товара
- title — название или заголовок продукта
- description — детальное описание продукции
- availability — наличие товара
- condition — условия
- price — стоимость
- link — ссылка на товар
- image_link — ссылка на изображение вашего продукта
- brand, mpn or gtin (include at least one) — уникальные идентификаторы, нужно ввести минимум один из них
1. Исходные ссылки на продукты
В первую очередь вам потребуется список ссылок на продукты. Для этого вы можете обратиться к sitemap.xml файлу.
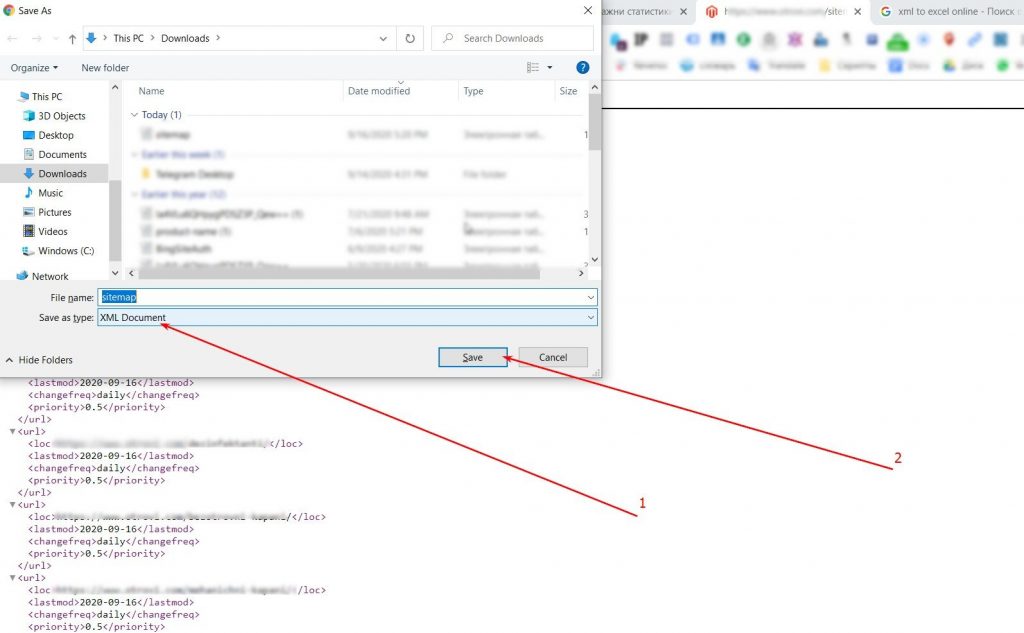
Сохраните xml карту и конвертируйте ее в обычный xlsx документ. В сети есть достаточно сайтов, которые могут выполнить это бесплатно. Например, этот. Полученные ссылки необходимо скопировать в Google таблицу.
Воспользуйтесь XPath для парсинга информации. XPath — это язык запросов к xml файлам, с помощью которого вы можете собрать необходимые данные. Обратите внимание, что синтаксис очень похож с простой навигацией по ОС Windows, поэтому у вас не должно возникнуть серьезных проблем. Таблица ниже поможет вам ориентироваться в базовых выражениях:
| Выражение | Описание |
| имя_узла | Выбирает все узлы с именем имя_узла |
| / | Выбирает от корневого узла |
| // | Выбирает узлы в документе от текущего узла, который соответствует выбору, независимо от того, где они находятся |
| . | Выбирает текущий узел |
| .. | Выбирает родителя текущего узла |
| @ | Выбирает атрибуты |
2. Парсинг заголовков
ImportXML(Url; XPath) — это простая формула в таблицах Google, с помощью которой можно импортировать данные из сторонних источников в форматах HTML, CSV, XML, TSV прямо через введенный URL и с применением необходимых выражений XPath. Таким образом, используя ImportXML вы можете парсить необходимую информацию из файла — title, description или другие параметры любого сайта.
Рассмотрим импорт на конкретном примере.
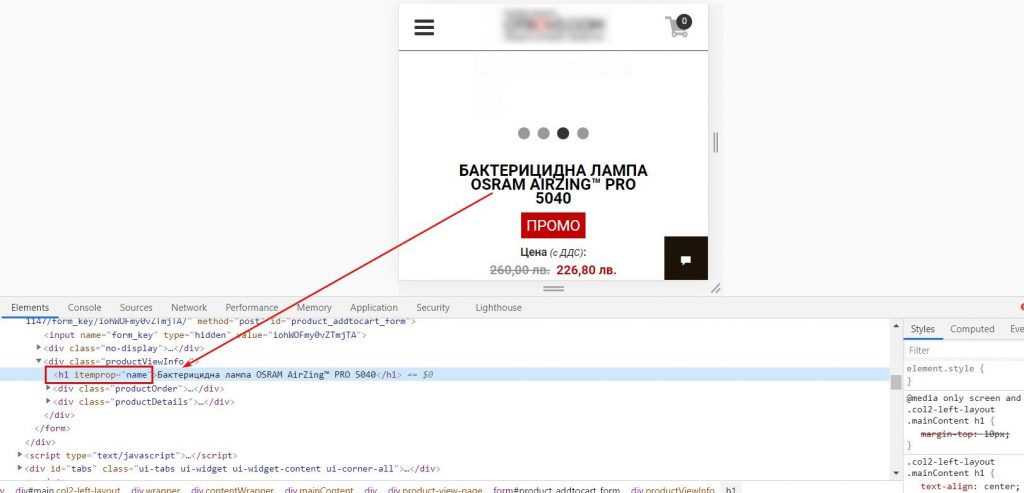
В нашем случае заголовок — это тег <h1>. Соответственно, нам необходимо использовать XPath: //h1. Это прямой путь к тегу h1 вне зависимости от его размещения на странице. Чтобы импортировать заголовок h1 в Google таблицу, необходимо прописать формулу:
=importxml(URL,»//h1[@itemprop=’name’]»)
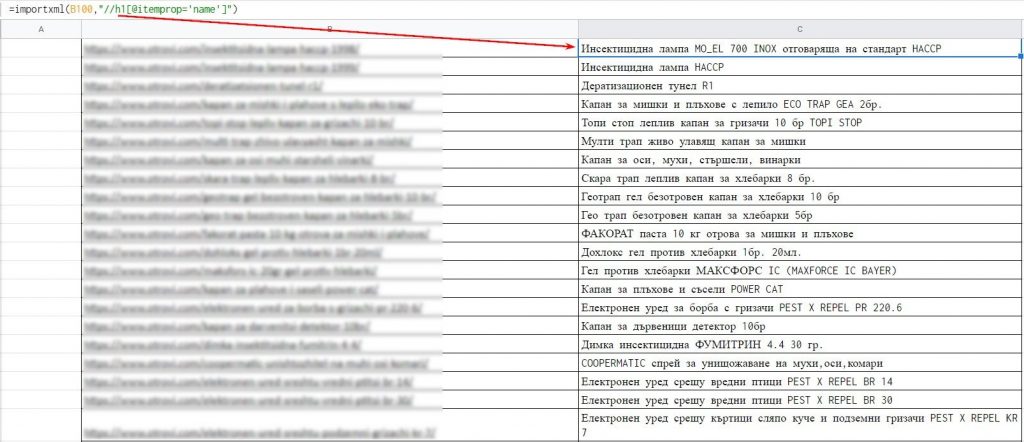
А теперь применяем эту же формулу для перечня страниц, которые мы собрали ранее.
3. Парсинг стоимости и наличия
Нужно понимать, что сайты могут быть построены по разному. Иногда цену и наличие можно спарсить одним запросом (один блок). Иногда приходится парсить отдельно. Рассмотрим следующий вариант:
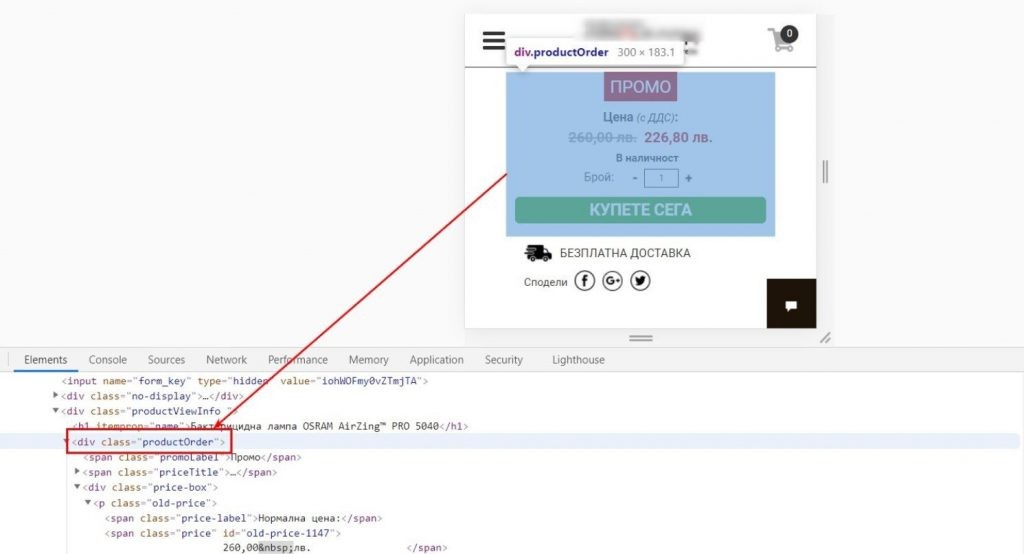
В этом конкретном примере необходима формула:
=importxml(URL,»//div[@class=’productOrder’]»)
Однако на скриншоте ниже вы можете увидеть, что не все данные отображаются корректно:
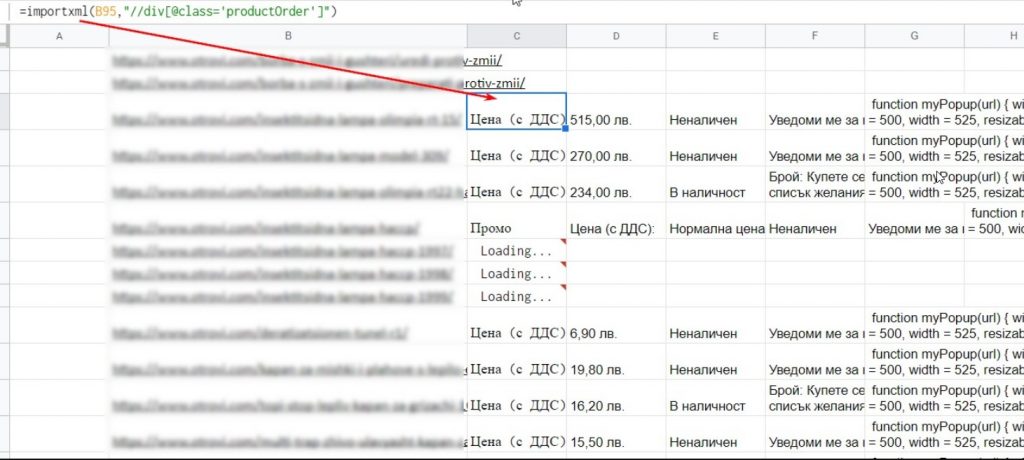
Эту ошибку мы исправим позже. На данном этапе она не критична.
Наличие
Чтобы отобразить наличие продукции, необходимо воспользоваться простой формулой IF. Если в информации, которую мы спарсили, присутствует фраза “в наличии” — указываем обозначение “In stock”. Иначе — указываем “Out of stock”.
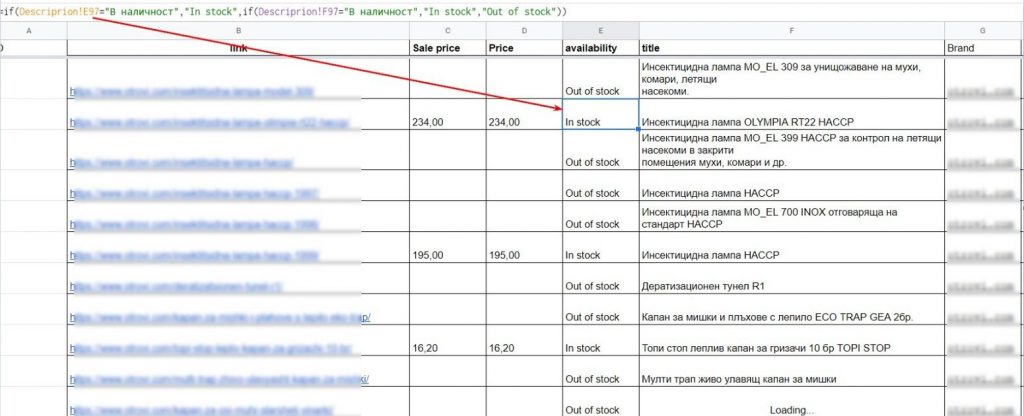
Стоимость
Если товар есть в наличии — указываем его стоимость в отдельной ячейке. Если нет — не стоит заморачиваться с ценой, поскольку это будет пустая трата времени.
В фиде стоимость товаров нужно указывать в определенной валюте. Как видно на скриншотах, в нашем случае цифры парсятся без валюты. Соответственно, при помощи функции Concatenate добавляем в конце цифр обозначение валюты. Вот формула вывода цен:
=if(Isblank(Data2!C96),,CONCATENATE(Data2!C96,Data2!I96))
Если в ячейке есть цена — добавляем обозначение валюты. Иначе — оставляем ячейку пустой. Проверить наличие данных в ячейке можно при помощи формулы Isblank.
4. Парсинг ID
Вам необходимо просмотреть карточки товаров и понять, какой у них присутствует уникальный идентификатор. В нашем случае — это SKU.
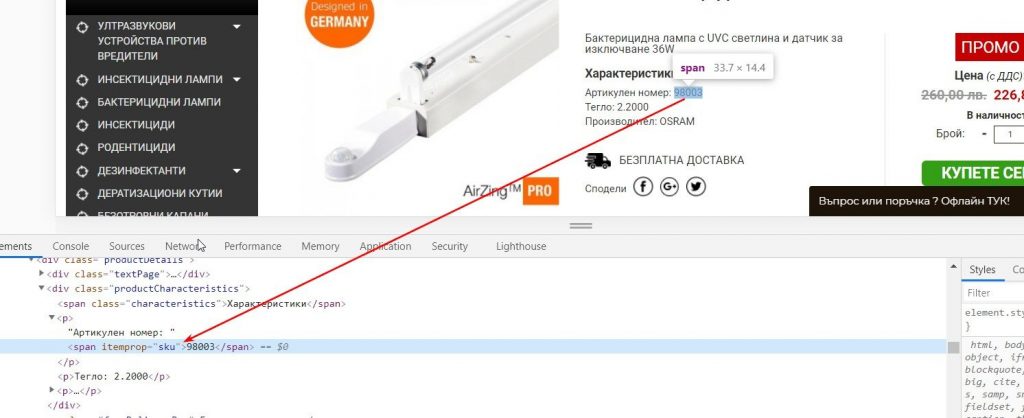
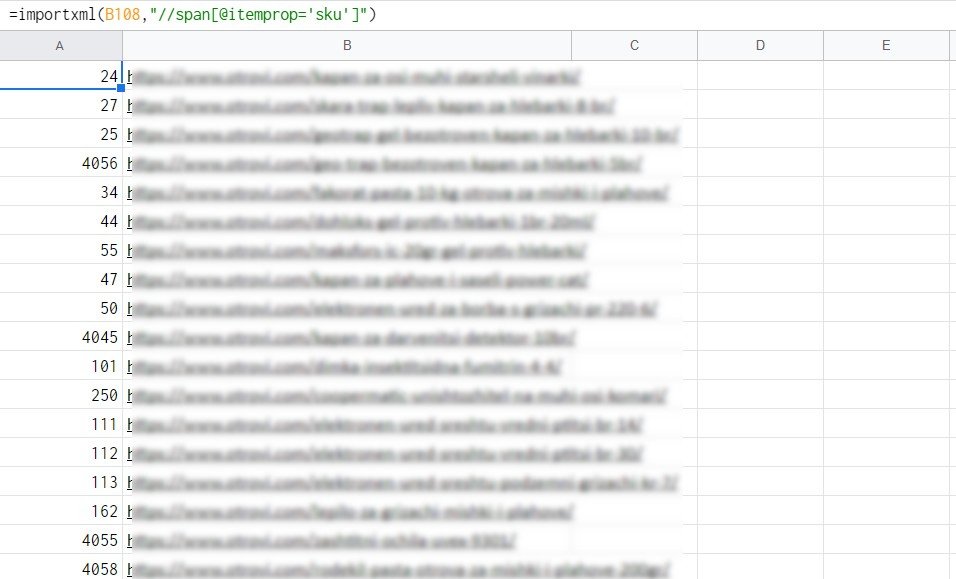
Используем приведенную ниже формулу, чтобы спарсить sku идентификаторы:
=importxml(URL,»//span[@itemprop=’sku’]»)
5. Парсинг ссылок на изображения
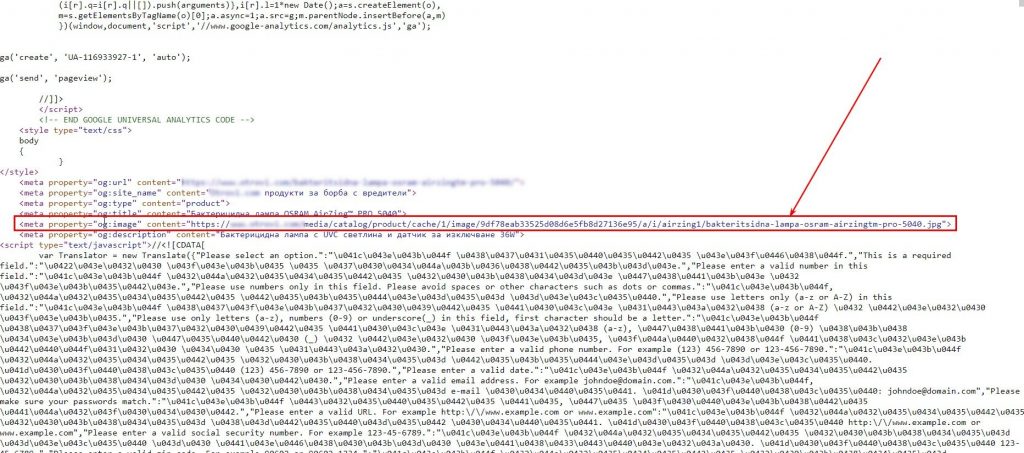
В нашем примере нашлось простое решение — парсинг URL из Open Graph. В вашем случае структура ресурса может быть другой. Однако смысл остается таким же, как и в предыдущих пунктах — найти необходимый элемент и спарсить ссылку на изображение.
В нашем случае это формула:
=importxml(URL,»//meta[@property=’og:image’]/@content»)
6. Объединение данных
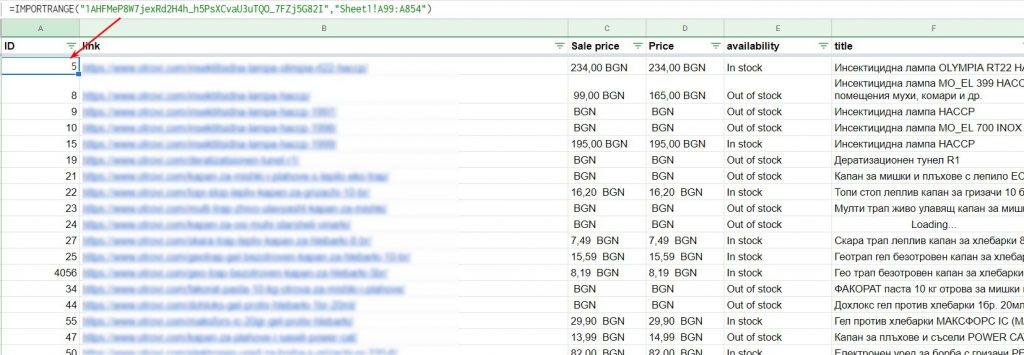
На этом этапе вам нужно объединить загруженные данные в одну таблицу, чтобы привести весь фид в порядок. Для этого вы можете воспользоваться следующей функцией:
=IMPORTRANGE( «URL таблицы»,»Sheet1!C3:C853″)
Как вы уже догадались, “Sheet1!C3:C853” — это расположение необходимых элементов в таблице, из которой вы хотите импортировать данные.
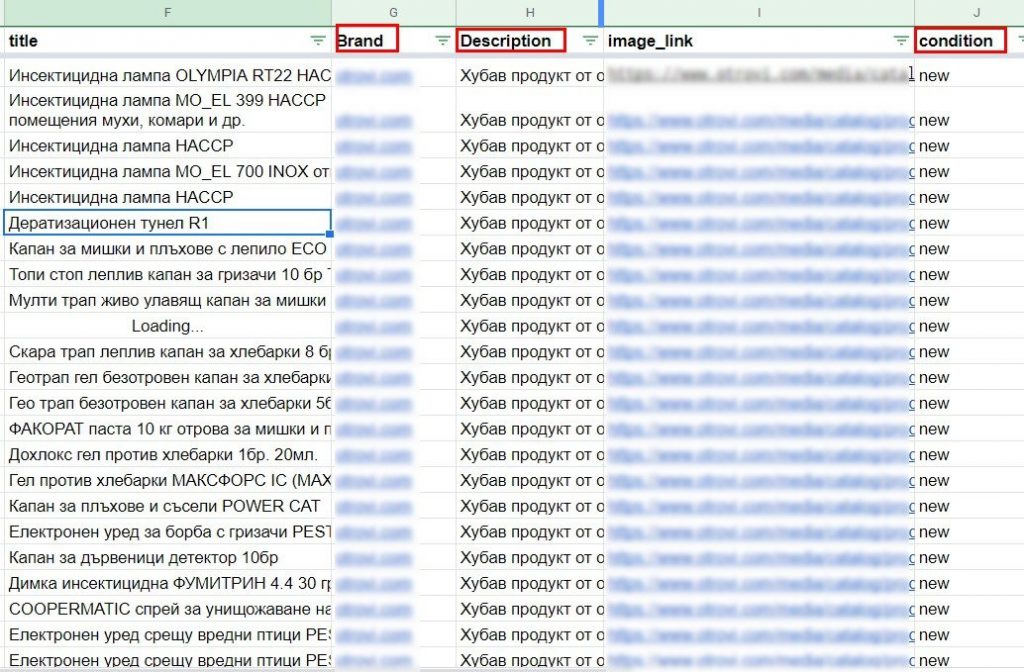
У вас останутся колонки “brand”, “description”, “condition”. Вы можете заполнить их следующим образом:
- brand — один идентификатор, который нужно протянуть по всем товарам.
- description — одинаковая общая фраза, которая сможет глобально охарактеризовать все продукты. Например: “Качественная продукция от ведущих производителей”.
- condition — указывайте new.
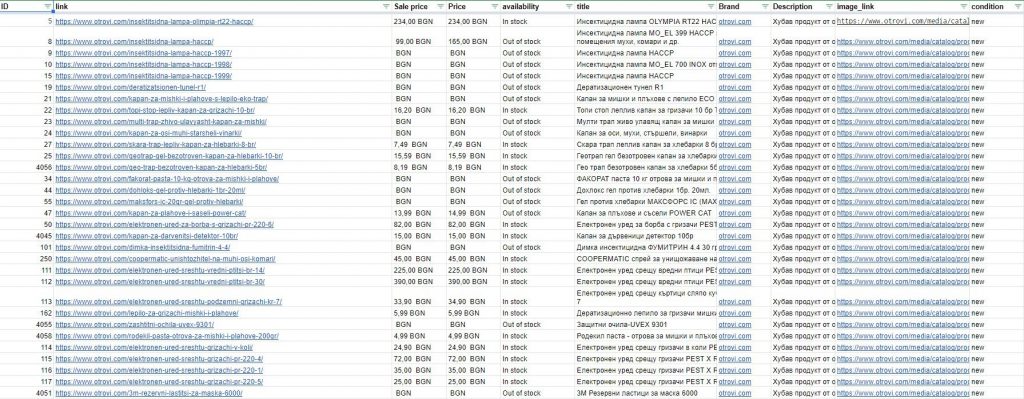
Готовый фид должен выглядеть следующим образом:
Теперь подготовленный файл загрузите в Facebook. В результате у вас должна появится окошко с приблизительно аналогичным содержимым:
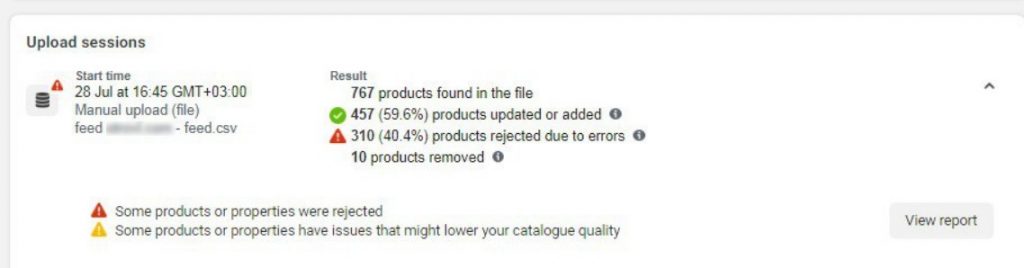
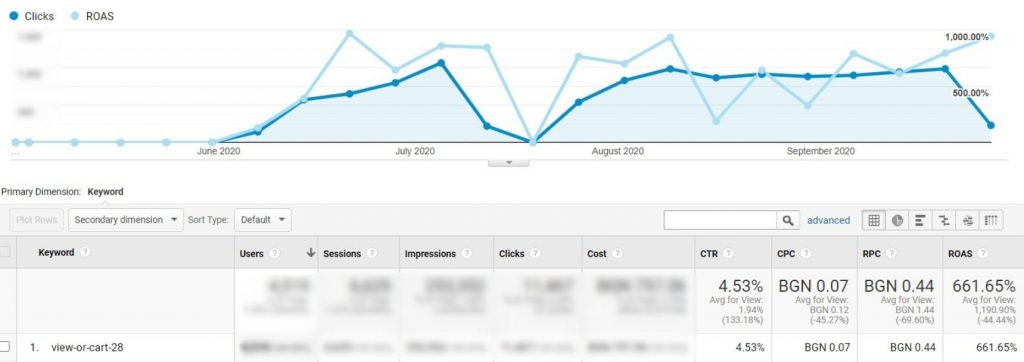
Вы сможете увидеть количество продуктов в наличии и прочие данные. На скриншоте ниже наглядно показана работа подобного фида за 4 месяца.
Рекомендую подписаться на наш Telegram канал, чтобы не пропустить интересную инфу — https://t.me/traffnews
Можно отметить сразу несколько преимуществ:
- Во-первых, все абсолютно бесплатно и без привлечения сторонних специалистов либо сервисов.
- Во-вторых, высокий уровень безопасности. Вам не нужно делиться доступом со сторонними людьми или сервисами.
- В-третьих, вы можете собрать кастомный фид в сжатые сроки.
Без минусов тоже не обойтись:
- Чем больше данных вам нужно собрать — тем больше времени займет этот процесс. Он однозначно не подойдет для крупных объемов.
- Если сайт обладает различными инструментами защиты от парсинга, он может заблокировать доступ к получению данных.
- Все дальнейшие правки придется вносить вручную.
Так или иначе, это метод, который работает на практике и не требует от вас каких-либо серьезных знаний, за исключением базовых понятий XPath.









Хоть программирование знать не обязательно, но базовые принципы и логика действительно должны быть подключены, чтобы самостоятельно разобраться и запустить по-настоящему толковый динамический ремаркетинг. Идея мне понравилась, поэтому сейчас мы с партнером активно думаем на ее реализацией в своем деле. Поскольку у нас нет знакомых программистов, то раньше приходилось платить приличные деньги отдельным специалистам. Теперь хочется сравнить, какие же будут результаты, если запустить ремаркетинг именно самостоятельно через инструментарий Гугла. Хочется верить, что всё получится.